
GraphQL Logo. Source: Facebook, BSD <>, via Wikimedia Commons
At ��������Ƶ, we deliver high quality user experience to our customers by constantly improving both our product and the way we work. We also believe in learning from each other. That's why we're sharing the steps we took and the lessons we learned to improve our GraphQL development workflow.
What is GraphQL?
GraphQL is a data query and language mutation that aims to improve the way a backend exposes its data to a client (frontend or mobile app). It’s now widely used across small to enterprise organisations because of its nature: it's both easy to adapt and easy to scale depending on the project maturity level. There's plenty of online resources discussing GraphQL and the benefits that have come from its adoption, but in this article we want to share a more specific point of view: how we found best practice in improving our GraphQL workflow efficiency.
Why improve a GraphQL workflow?
As developers, when we first look at new technology, we more often than not are attracted to the benefits this technology will introduce, and we often forget to consider how we adapt and change our process to maximise those benefits. At the same time, if you ask developers if they're happy with a slow development process, no one ever says yes!
So what does this all mean?
It means adopting GraphQL is only one part of the job. The other is fine-tuning the development workflow to make it “efficient”. For us, GraphQL is a critical part of our stack, and we've found that a regular audit and refactor of our GraphQL process has had a positive impact on our development process.
Here's what we've learned:
1. Define input params with Parameter Object pattern
While defining GraphQL queries and mutations in the schema, it's pretty common to have several input arguments. Let’s consider this example we had in our schema:
.png)
Though our project did grow, we found ourselves in a situation where the number of signature arguments increased in an exponential way. This caused compromises in the code readability across the team and also made it hard to later refractory this code:

Our solution was to opt-in to the , which aims to replace a list of arguments with an object containing these arguments.

Having this in place simplified the query and mutation readability, as well as the way we consumed it on the frontend.
2. Give consistent response types with good error-handling support
Since GraphQL aims to improve the way data is consumed, it's also important to define a common, predictable way the results are returned.
Inspired by , we created an envelope that consistently returns results and error messages in a way that is easily understood by our frontend developers. We also plan to use GraphQL Union to define different views of the error depending on conditions.
3. Use batch requests over a custom GraphQL query
During the user interface build, you might find you need different data to exist in the frontend at specific times.
We faced this issue, and our initial approach was to create a custom query / resolver that internally aggregated many other GraphQL queries. Though this approach worked, we found that a major downside was that frontend developers may have to wait until the backend implementation is complete. We also found that, for backend developers, there may be a need to add a new testsuite scenario before delivery of the code.
Our current approach relies on GraphQL Batch operations, where the client (frontend) builds its own (batch) query that is sent to the backend. The results are returned back to the client in a shape defined by the frontend developer. We've found this is a very beneficial approach, as it allows GraphQL to use the fundamentals of compositional programming. Indeed, we were able to build a new function by composing multiple other functions already existing in the backend (and already tested).
4. Take advantage of the GraphQL Code Generator tools
Few developers are aware that GraphQL came with powerful code generator tools.
In our initial frontend GraphQL implementation the developer was in charge of defining query and fragment in order to consume a GraphQL query or mutation. This worked fine, until we had to deal with multiple queries and mutations, as well as code refractory. We quickly realised too much time was spent writing this code and we looked for a solution to automate it.
Luckily, the GraphQL code generator saved us. This tool came as a very user-friendly CLI generating ready to use query/mutation/fragment for different languages. In our case we are now able to generate all TypeScript queries and mutations with their own fragments automatically. This generated code is then used from our backend-testsuite and validated with a contract-testing strategy against our backend. This makes sure that the code is bug-free at the moment the frontend developer will use it.
Conclusion
GraphQL is a relatively young technology that had a huge impact on many company in just a fews years. I’m expecting to see more and more changes to land in GraphQL specification very soon, as well as in ApolloServer and ApolloClient. Because of this it’s essential to have regular audits looking at how a team uses GraphQL so as to empower developers to improve not only our own work but also the way we work.
Put simply, we want to stop using old methodology with new technology.
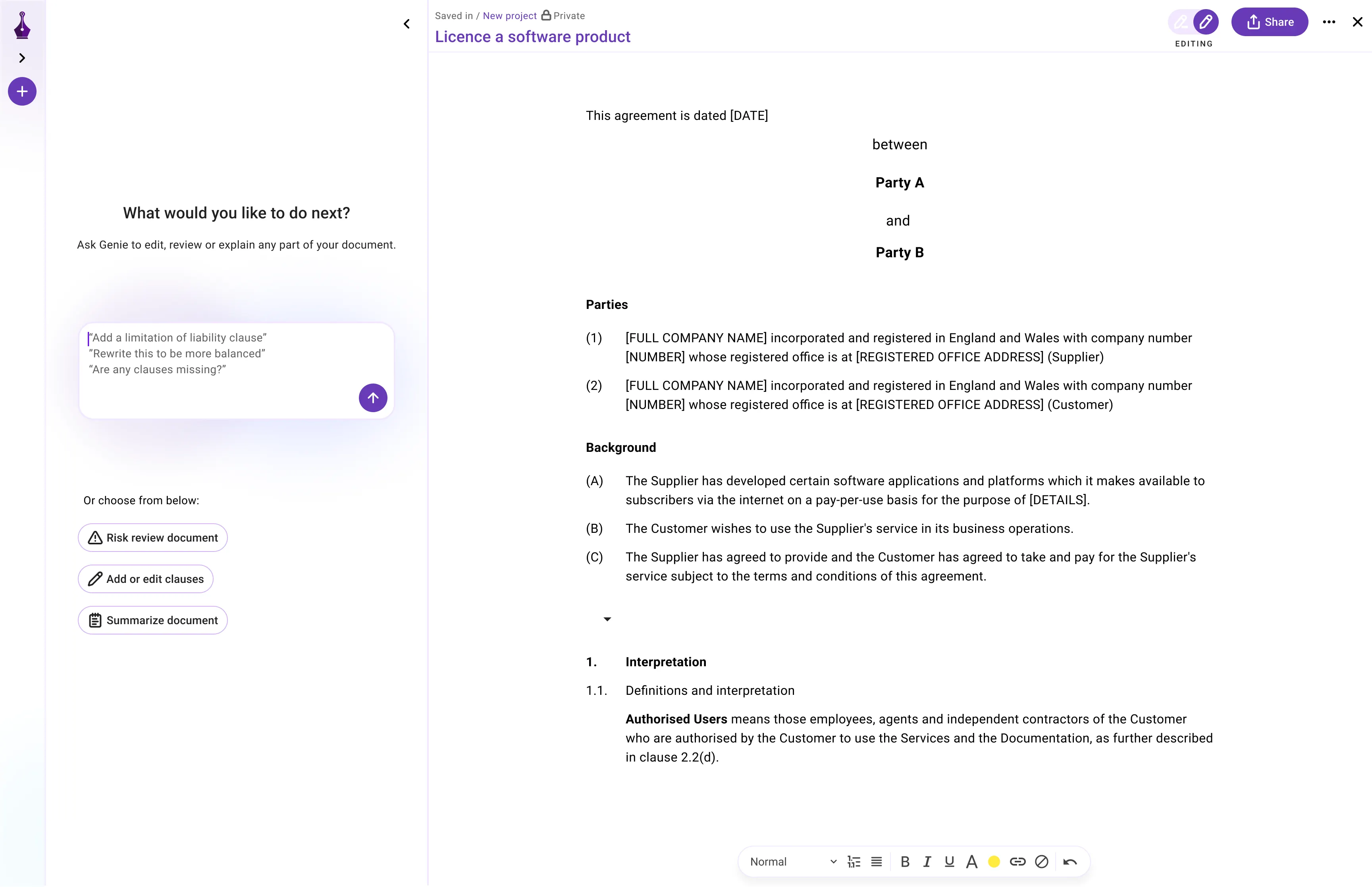
Interested in joining our team? Explore career opportunities with us and be a part of the future of Legal AI.
Interested in joining our team? Explore career opportunities with us and be a part of the future of Legal AI.
Download our whitepaper on the future of AI in Legal

Beyond the Screen: How Agentic AI Will Reshape User Interfaces
Related Posts

The 8 Best AI Tools for Cutting Business Costs in 2025
The 5 best business productivity-boosting AI tools in 2025
